Blog
What an AI-Era PM Actually Does
Something That’s Been Bothering Me
I’m a PM at a startup that builds AI products for cross-border trade. Last quarter, the foundation model we sit on top of shipped yet another new version. OpenAI, Anthropic, Google, one of the Chinese labs — doesn’t matter which. The day the new model went live and got wired into the product, the product team barely blinked.
Meetings still happened. Specs still got reviewed. The roadmap still shipped on schedule. The model went from X to X+1, and the product didn’t change one bit. All we’d done was drop a smarter model into a workflow we’d already nailed down.
That was the day it hit me: we are not an AI-native organization, and we are not building an AI-native product. To put it bluntly, we’re a traditional software company wrapping an AI API in SaaS clothing.
And it isn’t just us. Almost every Chinese startup flying the “AI” banner today is in exactly this state. Behind that state sits a question the PM field hasn’t really sat down and talked about:
What does an AI-era PM actually do?
In the Internet Era, PMs Defined “Good” With Data
For the past decade, the ByteDance-style PM playbook was the most polished product methodology in the Chinese internet.
The core idea is simple. User behavior generates data, and the data tells you what works and what doesn’t. A/B tests, retention, DAU, ARPU — at bottom, this whole stack of metrics lets users vote with their feet, and from those votes you back out what counts as a “good product.”
What made it powerful? It turned “what is good” from a subjective call into an objective measurement. A PM didn’t have to rely on experience, gut, or the boss’s taste. The data decided for you.
But that approach rests on three assumptions: you need a huge user base producing statistically significant data; user behavior has to be capturable and quantifiable; and the distribution of that behavior has to be reasonably stable — not A today and B tomorrow.
AI products satisfy none of the three.
In the AI Era, the User Experience Is Welded to the Model’s Behavior
The experience of an internet product is decided by its UI. Where the buttons go, how the flow runs, what the copy says — the PM calls all of it. The model, in that world, is just a component in the back end, no different from a database or a cache.
AI-native products don’t work that way. Whether an AI sales assistant writes a good email, whether the code a coding Agent produces actually runs, whether a chat product’s answers have any warmth to them — none of that is decided by the UI. It’s decided by the model, output by output.
In other words, the user experience and the model’s behavior are now coupled. You can no longer do what traditional PMs did and discuss “user experience” and “technical implementation” as two separate things. In an AI-native product, they’re the same thing.
That coupling has one immediate consequence: the thing a PM uses to define a product’s value has changed.
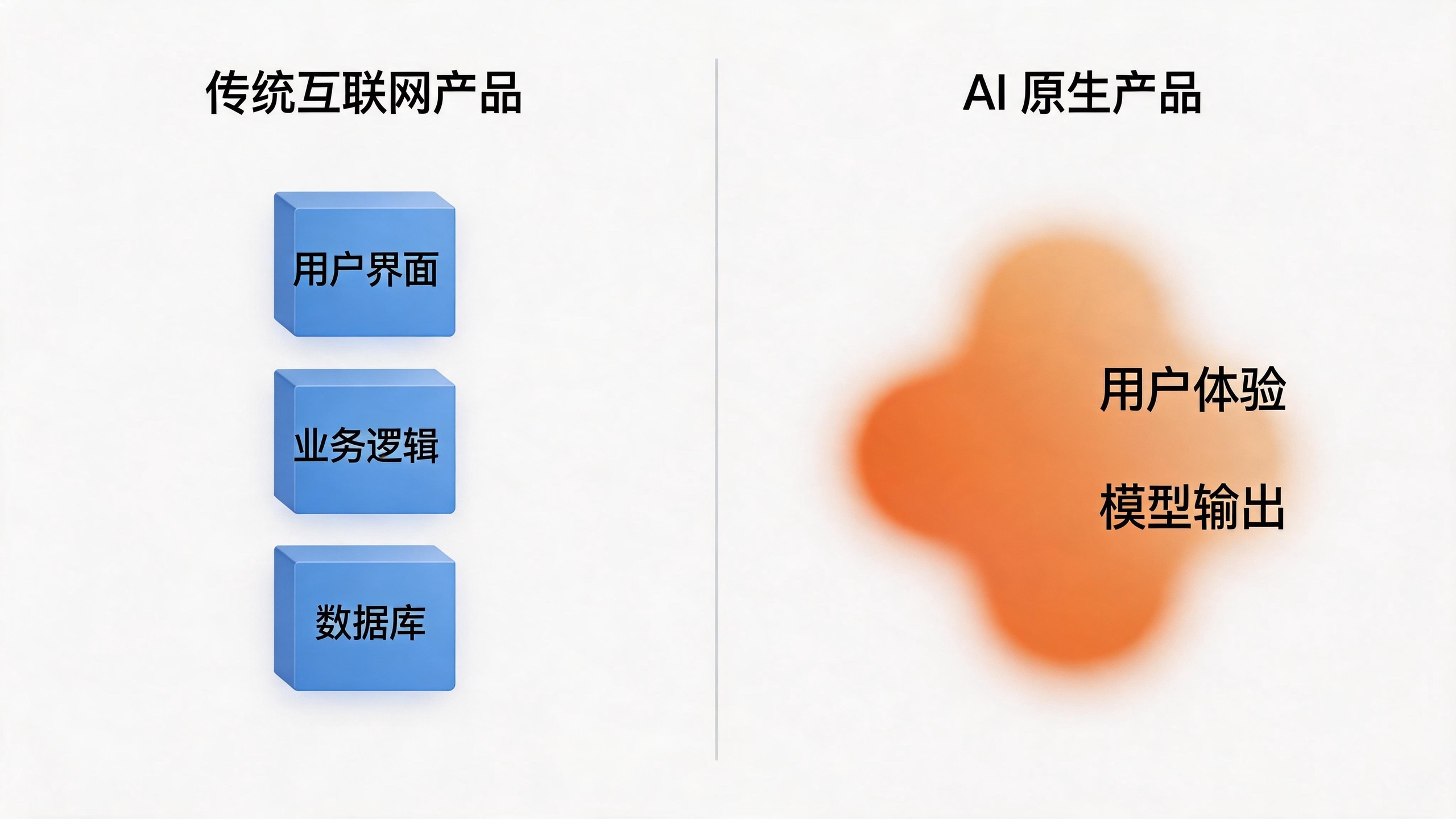
In the internet era, a PM defined the product through a PRD. A PRD is written for humans — for designers, for engineers, for the boss. So in the AI era, what does a PM use instead?
The Answer Is the Benchmark
The word sounds like it belongs to the ML engineers. Most PMs in the Chinese AI scene read “benchmark” as “a test set for measuring model capability” and figure it’s something the researchers should worry about.
Wrong. In the context of an AI product, a benchmark is, at its core, the thing that turns “what makes a good product” from a subjective judgment into a spec a machine can execute. It isn’t a test set. It’s a PRD in code form.
Writing the benchmark for an AI sales-email feature really just means answering a handful of questions:
- What dimensions does a “good email” have to satisfy? Relevance, personalization, persuasiveness, compliance, and so on.
- How do you score each dimension? What does a 5 look like? What does a 3 look like?
- What about edge cases? If the customer is European versus Southeast Asian, is the standard the same?
- Which dimensions, and at what weights, best predict that “the customer actually replied”?
Answer those questions and you’ve finished defining the product. Once the benchmark is written, the requirements are done — everything left is an engineering problem.
This is why Anthropic’s CPO, Mike Krieger, said in an interview: “If you interview for a PM role at Anthropic, we want to see how you think about evals. There aren’t enough people who can.” OpenAI’s CPO, Kevin Weil, put it even more bluntly: “Writing evals is going to become one of the core PM skills.”
Those two lines aren’t industry leaders working the crowd. They’re a warning to everyone: in the AI era, the very thing a PM works through has shifted underneath us.
A Benchmark Has Two Layers
What actually excites me isn’t “PMs need to write evals.” That’s just the surface.
The deeper point is this: a good AI benchmark is never one thing. It’s two layers.
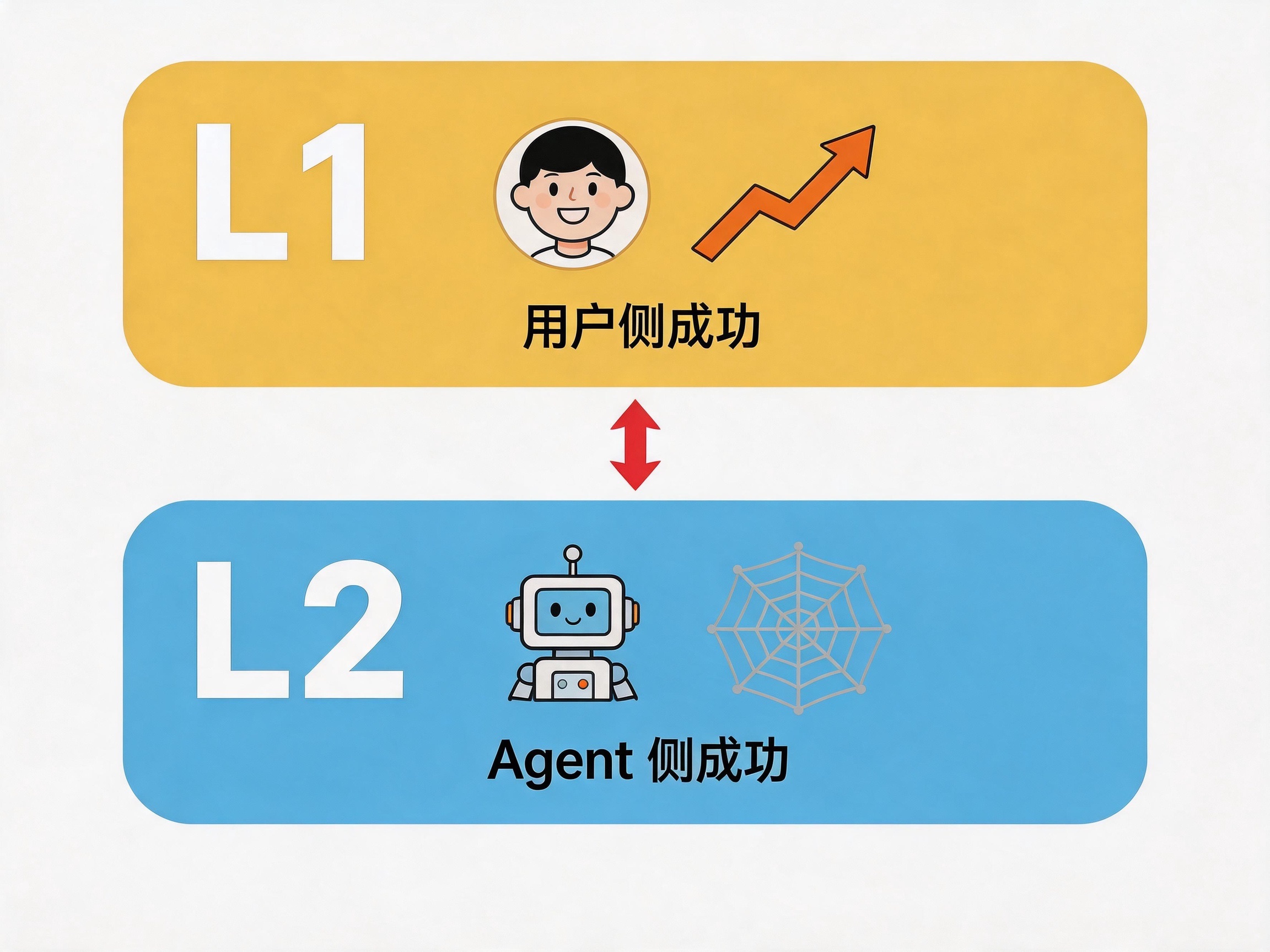
The first layer I call L1: success on the user’s side. The customer replied, closed the deal, renewed, told a friend. This is the end effect the product produces in the user’s life.
The second layer, L2, is success on the Agent’s side. The output meets the spec, the information is complete, the tone fits, there’s no hallucination. This is the Agent “doing the thing right” at the level of technical execution.
These two layers come apart all the time, and the way they come apart is deeply counterintuitive.
Here’s an example. An AI-generated sales email might be a perfect score across every L2 dimension — relevance 5, compliance 5, tone 5 — and the customer still doesn’t reply. Meanwhile another email might be a little rough on L2, yet because one sentence in it lands squarely on a real pain point, the customer writes back.
L2 is a process metric; L1 is an outcome metric. L2 is near-term, decomposable, observable. L1 is far-off, holistic, cuts across situations. To put it even more plainly: L2 asks whether the product is doing things right, and L1 asks whether the product is doing the right things.
Drucker made this distinction sixty years ago. In the AI era it finally has a concrete, executable form to live in: the two layers of a benchmark.
Why Only a PM Can Do This Translation
Be honest with yourself for a second: the translation between L1 and L2 — whose job is it?
There are four candidates.
The ML engineer is great at L2. Writing the model is literally what they do. But they’re structurally bad at L1 — nothing in their training covers “deeply understand the user, the business, the situation.” Let an ML engineer define the benchmark and you get L2 with no L1: the technical numbers look gorgeous and nobody buys the product. Plenty of model companies post sky-high benchmark scores and ship products that flop, and this is exactly why.
The user researcher is great at L1 — studying users is what they do. But they don’t understand how the model works, so they can’t break “the user’s success” down into observable Agent behavior. Let a user researcher define the benchmark and you get L1 with no L2: the standard says clearly what we want, and engineering has no idea how to ship it.
The domain expert is great at defining L1 inside their own domain, but they usually can’t read the edges of what AI can do. Either they set a standard the model can’t possibly hit, or they miss a higher standard the model could actually reach.
The PM is different. From the day this role was born until now, the one thing about it that has never changed is this: understand the user, understand the technology, translate between the two.
In the internet era, a PM translated “user needs” into “product features” and handed them to engineers to build. In the AI era, a PM translates “the user’s success” (L1) into “the Agent’s success” (L2) and hands that to ML and engineering to build.
Structurally, this translation is something only a PM’s training can catch. The ML engineer, looking up from the tech, can’t reach L1. The user researcher, looking down from the user, can’t reach L2. The domain expert, looking sideways from the business, can’t reach either end. The PM is the only role trained to watch both layers at once.
So “an AI PM has to understand evals” isn’t a skill upgrade. It’s the essence of the PM role, finally made visible in the AI era.

The PM Field Is Quietly Splitting in Two
If you buy the argument so far, you arrive at a conclusion that doesn’t feel great: the PM profession is splitting into two kinds, and the gap between them widens every month.
One kind of PM — call it Type A — is still stuck in the old paradigm of “file requests, chase progress, read the dashboard.” To them, AI is a black box. They write a line like “the AI should be friendly and polite” and toss the rest over the wall to the ML engineers. This PM can still get by inside an AI-wrapper product (SaaS with an AI assistant bolted on), but in a genuinely AI-native organization they’ll be pushed to the margins.
The other kind, Type B, does work whose core is defining how the model should behave and designing the eval system. They don’t just interact with the model — they define the product in the model’s own language. They can write a prompt, design a rubric, and drive ML decisions with data. In an AI-native organization, this is the person who’s actually running the product.
OpenAI’s CPO offered a verdict on this in an interview: “The gap between these two kinds of PM is widening every month. AI companies need Type B. They can’t afford to keep people who ship on vibes.”
Let me translate that. Five years from now, a PM who doesn’t understand evals will be like a PM today who doesn’t understand SQL. Still employable — but no longer on the main battlefield.

Which Kind of PM Do You Want to Be
I didn’t write this to put a shine on the “AI PM” label.
Honestly, I have no particular attachment to the label itself. What I care about is something more concrete: only once you can take an AI product’s good-versus-bad and cleanly split it into two layers, L1 and L2, and then define it in code form — only then have you really entered the design language of AI-native products.
Otherwise, what you’re building is still SaaS. You’ve just stuffed a model into it.
I’m only at the entrance to this road myself. The ToB Agent evals I do every day at the trade company, the Chinese tool-calling benchmark I’m building for my master’s thesis, the galgame skill I tinker with on the side — to an outsider these look like three different things. At bottom they’re the same thing: turning fuzzy standards of judgment into executable instructions and measurable metrics.
This is the real inner craft of a PM in the AI era.
So this piece isn’t an answer. It’s an invitation. Have you ever written a complete eval? Can you split your own product’s “good” into L1 and L2? Your next job — do you want it to be Type A, or Type B?
If you’ve been turning these questions over too, I’d love to talk.